EDA vs Data Preprocessing: What's the Difference?
By Mbali Kalirane on
Both Exploratory Data Analysis (EDA) and data preprocessing play important roles in the data cleaning pipeline, but they serve different purposes. In this article, you will learn the difference between EDA and data processing, and how each process is used differently in data preparation. You’ll understand the steps involved in each process, and you’ll learn how to implement these steps in Python.
Table of Contents
- What is Exploratory Data Analysis (EDA)?
- What is Data Preprocessing?
- Example of EDA vs Data Preprocessing
- The Process of EDA
- The Process of Data Preprocessing
- Conclusion
What is Exploratory Data Analysis (EDA)?
The aim of EDA is to get an understanding of the characteristics and structure of your data. It’s the process of analyzing your data to look for patterns in the data, evaluate how your data is distributed, and look for potential errors in your data.
What is Data Preprocessing?
Data Preprocessing is the process of fixing the errors discovered during EDA. It consists of a variety of data cleaning processes, such as removing missing values from the dataset, or fixing incorrectly written values. Data preprocessing is beneficial for preparing the data for the model training process. For algorithms to effectively process your data, it must be clean and well-prepared.
Example of EDA vs Data Preprocessing
Let’s take an example of a classification dataset, which aims to determine the likelihood of a heart attack based on a patient’s health information and characteristics. Before modelling this data, EDA had to be performed on this data in order to identify issues in the data. Pre-processing then had to be applied on the data to fix the identified issues. Let’s take a look at the steps for performing EDA and preprocessing on data.
The Process of EDA
The EDA will consist of finding the characteristics of the dataset, this includes checking for the following:
- Viewing the data
- Dataset proportions
- Missing Values
- Data types
- Duplicate values
- Inconsistent values
- Data Distribution
Viewing the Data
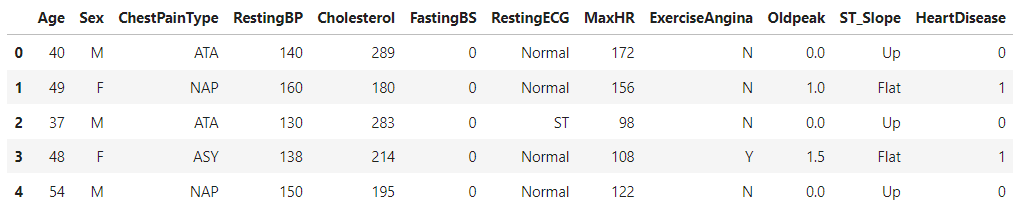
Suppose the dataset is named data.
Firstly, you need to view your data. For this, you can use data.head().
Check for Dataset's Proportions
Evaluate the number of rows or columns in the dataset.
You can use .shape() to determine the dataset’s proportions. Thus, you’ll have:
data.shape
The output below shows that the dataset has 918 rows and 12 columns.
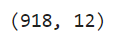
Check for Missing Values
Evaluate the dataset for any missing values.
You can check for missing values using isnull().values.any(). This will tell you whether the dataset has any missing values by returning either a True or False. Thus, applying this to the dataset, you’ll have:
data.isnull().values.any()
As can be seen by the output below, there are no missing values in the dataset:
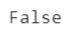
Check for Data types
Check the data types of each variable and identify variables which need to be converted to numerical types.
You can use dtypesfor checking the data types of each variable. Applying this to the data, you’ll have:
data.dtypes

As can be seen from the above output, ST Slope, ExerciseAngina, RestingECG and ChestPainTypehave non-numeric data types, and will have to be converted to numeric data types.
Check for Duplicate Values
Check if any instances or rows have been duplicated.
For this, you can use the method .duplicated(), as follows:
This code generates a statements saying whether the dataset contains duplications or not.
From the above output it’s clear that the dataset contains no duplicate rows.
Check for Inconsistent Values
Inspect the categorical variables to identify any incorrectly written, misspelled or repetitive data.
For this, you can use a For-loop to check the unique values of each categorical column in the dataset.
From the output below, you can see that there does not appear to be any inconsistent values in any categorical column of the dataset.

Check for Outliers
Check for the presence of outliers in the numerical variables of the dataset.
To do this, you can use boxplots as follows:
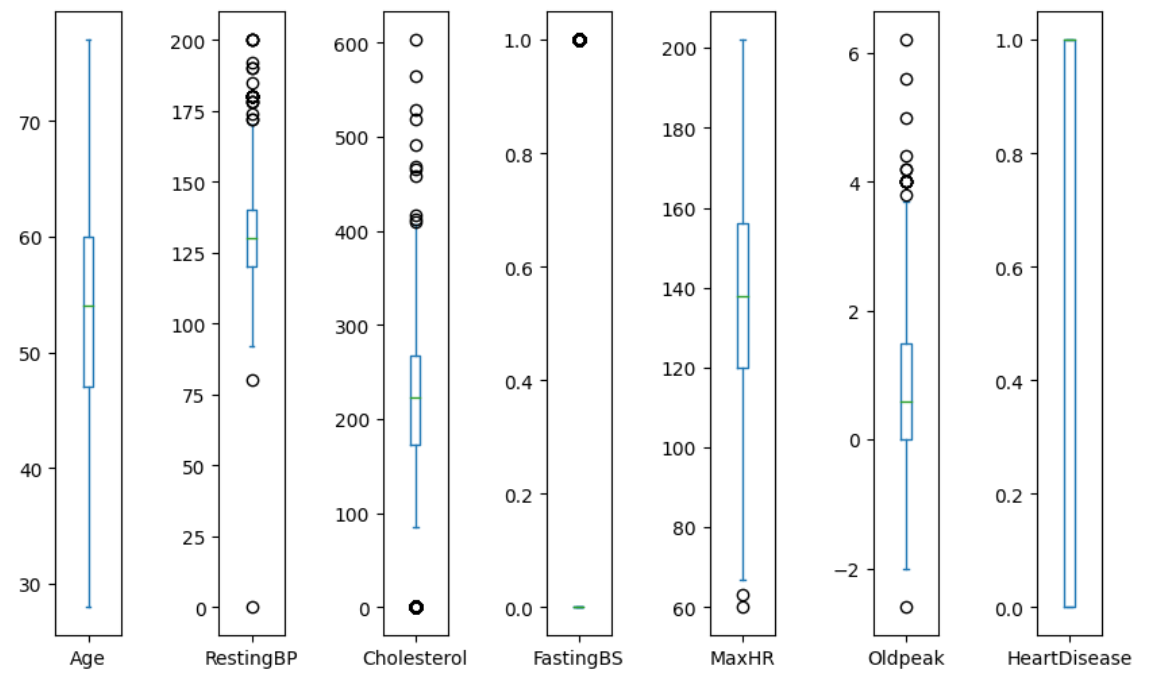
The outliers are represented by the hollow circles in each boxplot. And as can be seen from the boxplots, there are outliers in each of the numerical columns, except for Age.
Check the Data's Distribution
Evaluate the balance of the data, particularly the target variable. Evaluating the balance of the target variable is important for identifying potential biases in the data, especially for classification problems.
You can use a bar chart to evaluate the proportion of each class in the target variable:
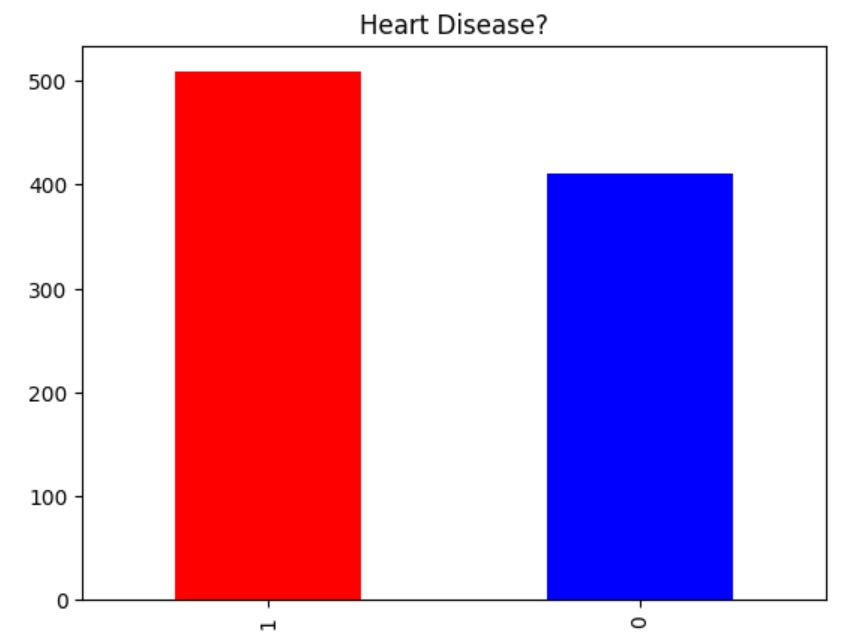
To get a more concrete understanding of the proportions of each class in the target variable, you can calculate the percentages for each class as follows:

As can be seen from the above output, the target column is just slightly imbalanced. In our dataset, the target variable comprises around 55% of data in one class and about 45% in another class. This indicates a relatively balanced distribution between the classes. Thus, applying a method to balance the data may be unnecessary.
The process of Data Preprocessing
After applying EDA to our dataset, we can see that the dataset presents several issues that need to be fixed and require preprocessing.
Issues Identified:
The problems identified in the data are as follows:
- There are outliers
- There are non-numerical variables
- There’s a sligt imbalance in the data
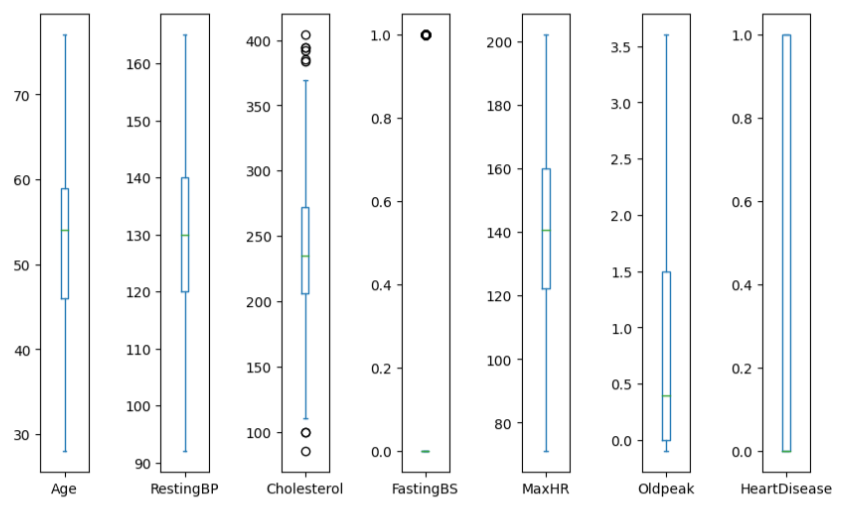
Remove Outliers
Remove Outliers from the dataset.
To do this, you can use the Inter quartile range (IQR). The IQR helps calculate upper or lower limits, allowing the identification and removal of outliers beyond these limits.
Thus, from our output, we can see that the outliers have been removed from the data:
Convert Categorical Data to Numeric Data
The dataset contains categorical variables, thus you need to convert these into numeric format.
You’ll need to convert the following categorical variables into numeric form:
SexChestPainTypeRestingECGExerciseAnginaST_Slope
Sex, ExerciseAngina and ST_Slope are nominal variables, and ChestPainType and RestingECG are ordinal variables.
Thus, for nominal variables, you can use get_dummies as the encoding method, and for ordinal variables, you can use OrdinalEncoder as your encoding method.
Encoding Nominal Data
Using get_dummies on nominal data:
Encoding Ordinal Data
Using OrdinalEncoder on ordinal data:
Thus, we have the following output of encoded data:
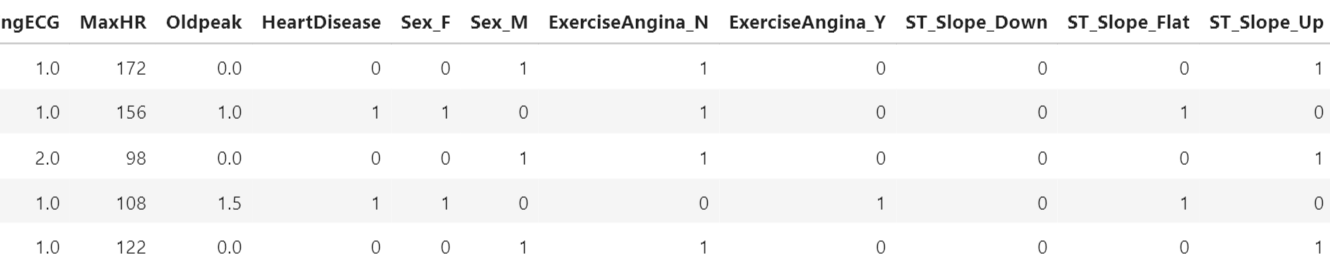
Balance the Data
Balance the target column. To do this, you can use an upsampling method as follows:
Conclusion
EDA is about exploring your dataset to understand its structure, issues and characteristics. Data preprocessing is about fixing the issues found the data, and cleaning the data in preparation for the modelling stage.
In the above analysis, I identified the following problems from applying EDA: the presence of outliers, non-numerical data, and imbalanced data. During data preprocessing, I removed the outliers, encoded the non-numerical data and balanced the data.
However, it’s important to note that the order of some data cleaning processes need to be carefully considered. For example, the removal of outliers from a dataset can impact data balance, and vice versa. Thus, data balancing will need to be applied after the removal of outliers.
Also, careful consideration is needed when choosing between the two approaches. If outliers come from measurement errors or anomalies, removing them may be necessary, irrespective of class imbalance. However, when faced with significant class imbalance, such as a 90:10 ratio, addressing this issue takes precedence.
In cases where both issues exist, employing both data balancing techniques and outlier removal may be necessary. After applying outlier removal, you may need to check you data balance again.